BuidlerDAO:大型语言模型LLMs使用经验
文章速览
01/ LLM
02/ ChatGPT Prompt
03/ 组合 Agent
04/ Prompt 微调
05/ 总结
06/ 参考文献
LLM
大型语言模型(LLM, Large Language Model)是利用海量的文本数据进行训练海量的模型参数。大语言模型的使用,大体可以分为两个方向:
A. 仅使用
B. 微调后使用
仅使用又称 Zero-shot,因为大语言模型具备大量通用的语料信息,量变可以产生质变。即使 Zero-shot 也许没得到用户想要的结果,但加上合适的 prompt 则可以进一步获取想要的知识。该基础目前被总结为 prompt learning。
大语言模型,比较流行的就是 BERT 和 GPT。从生态上讲 BERT 与 GPT 最大的区别就是前者模型开源,后者只开源了调用 API ,也就是目前的 ChatGPT。
两个模型均是由若干层的 Transformer 组成,参数数量等信息如下表所示。
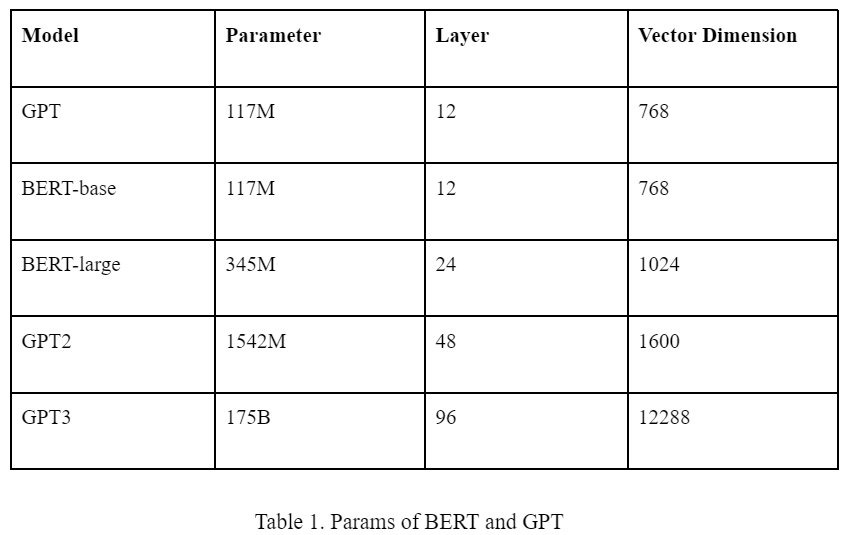
目前生态上讲,BERT 多用于微调场景。因为微调必须在开源模型的基础上,GPT 仅开源到 GPT2 的系列。且相同模型参数量下 BERT 在特定场景的效果往往高于 GPT,微调需要调整全部的模型参数,所以从性价比而言,BERT 比 GPT 更适合微调。
而 GPT 目前拥有 ChatGPT 这种面向广大人民群众的应用,使用简单。API 的调用也尤其方便。所以若是仅使用 LLM,则 ChatGPT 显然更有优势。
ChatGPT Prompt
下图是 OpenAI 官方提出对于 ChatGPT 的 prompt 用法大类。
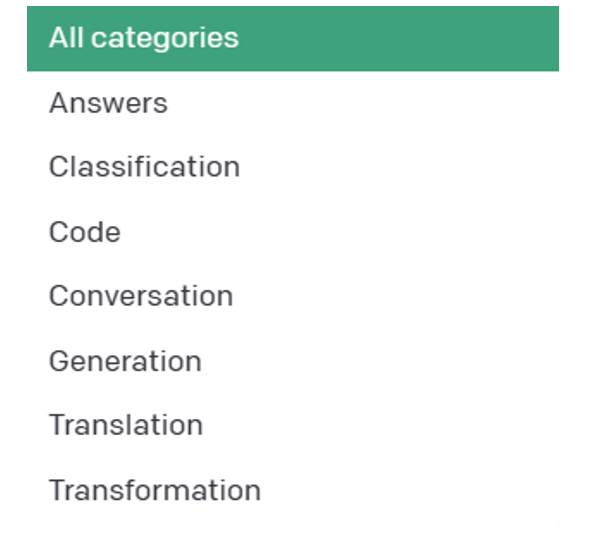 Figure 1. Prompt Categories by OpenAI
Figure 1. Prompt Categories by OpenAI
每种类别有很多具体的范例。如下图所示:
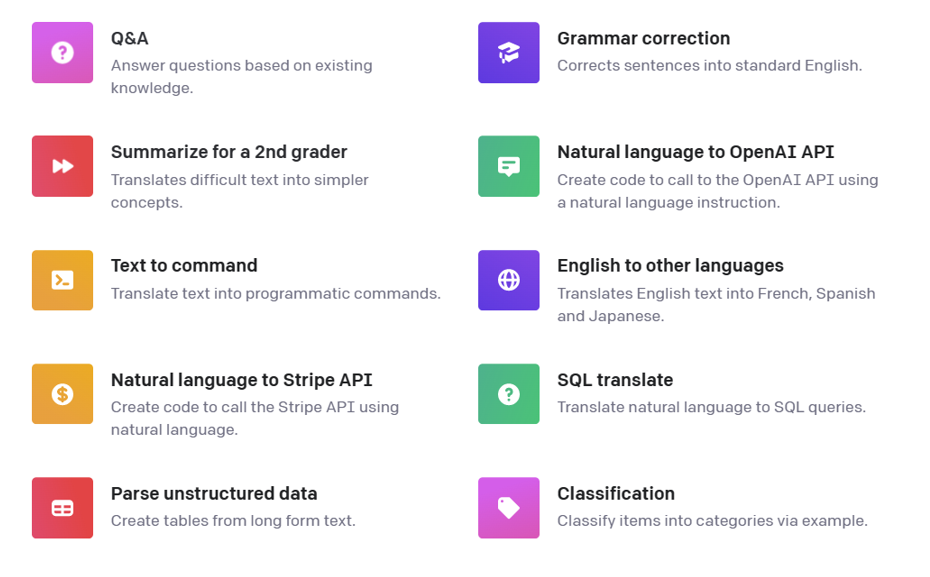 Figure 2. Prompt Categories Examples by OpenAI
Figure 2. Prompt Categories Examples by OpenAI
除此以外,我们在此提出一些略微高级的用法。
高级分类
这是一个意图识别的例子,本质上也是分类任务,我们指定了类别,让 ChatGPT 判断用户的意图在这
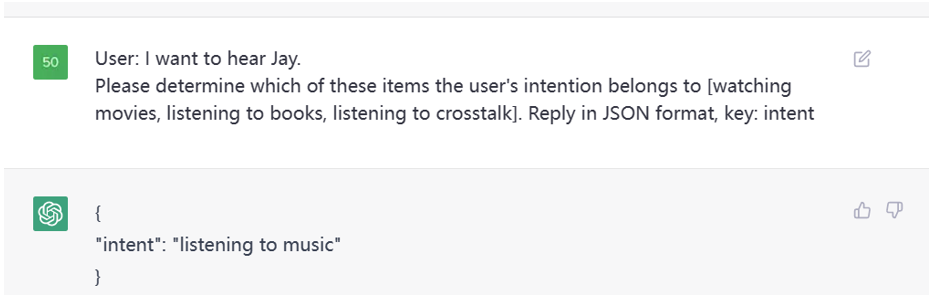 Figure 3. Prompt Examples
Figure 3. Prompt Examples
实体识别与关系抽取
利用 ChatGPT 做实体识别与关系抽取轻而易举,例如给定一篇文本后,这么像它提问。
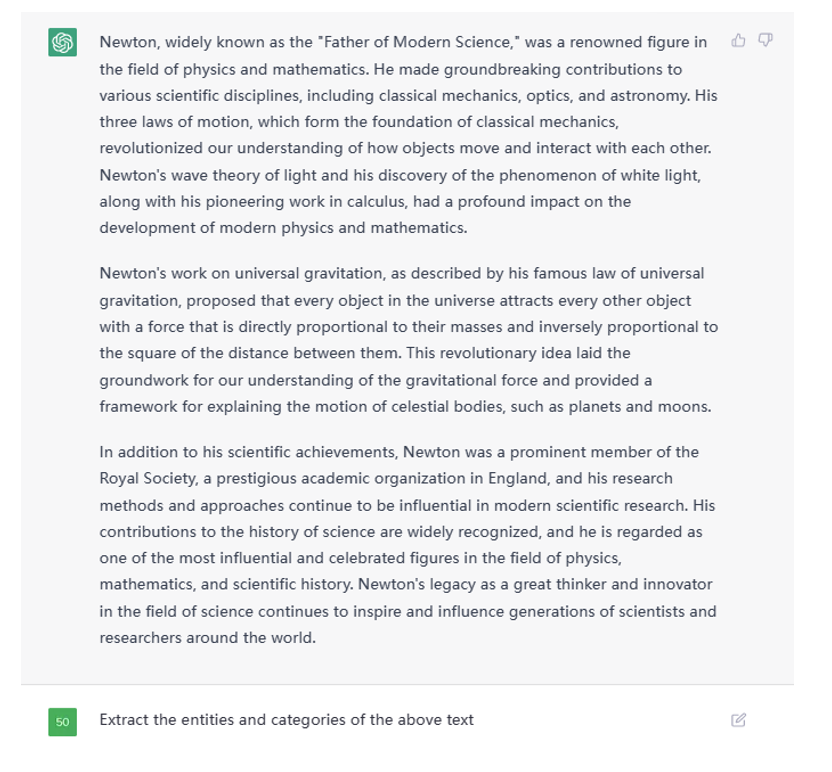 Figure 4. Example Text Given to ChatGPT
Figure 4. Example Text Given to ChatGPT
这是部分结果截图:
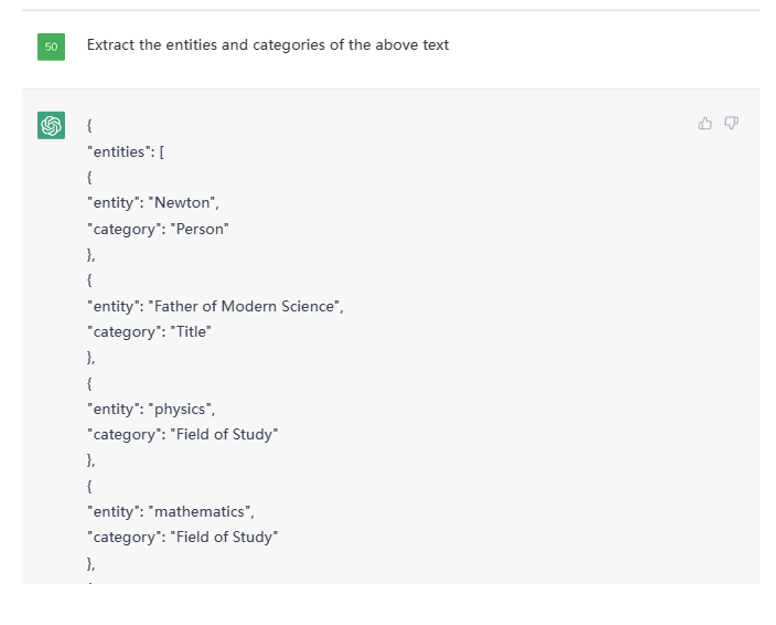 Figure 5. Partial Output from given Text on ChatGPT
Figure 5. Partial Output from given Text on ChatGPT
之后可以追问给他们的关系,例如:
 Figure 6.Asking relationship on ChatGPT
Figure 6.Asking relationship on ChatGPT
这样,一个大型的知识图谱便可轻松建立。
分析任务
如下图所示,我对 ChatGPT 提出了分析我目前需求的问题。
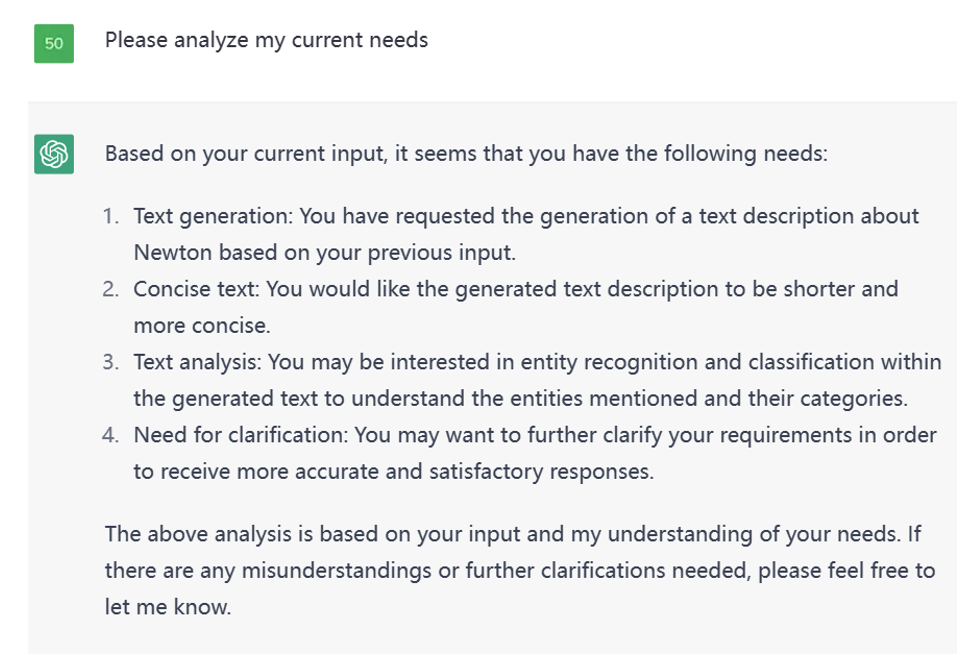 Figure 7. Result for needs request on ChatGPT
Figure 7. Result for needs request on ChatGPT
甚至还能让它给定分数。
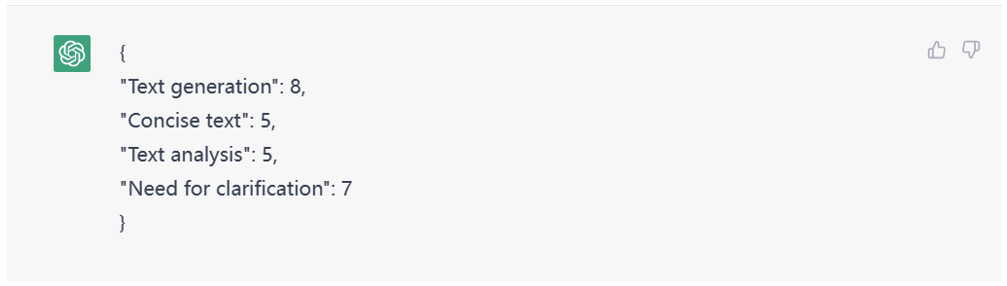 Figure 8. Scoring to evaluate the identified needs
Figure 8. Scoring to evaluate the identified needs
除此以外还有数不胜数的方式,在此不一一列举。
组合Agent
另外,我们在使用 ChatGPT 的 API 时,可以将不同的 prompt 模板产生多次调用产生组合使用的效果。我愿称这种使用方式叫做,组合 Agent。例如 Figure 1 展示的是一个大概的思路。
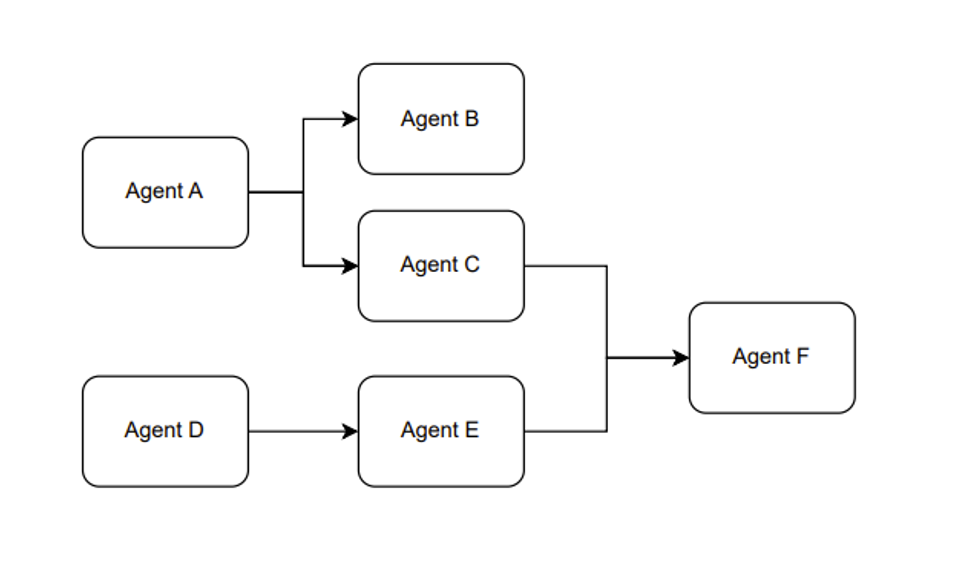 Figure 9.The Paradigm of the Combination Agent
Figure 9.The Paradigm of the Combination Agent
具体说来,例如是一个辅助创作文章的产品。则可以这么设计,如 Figure 10 所示。
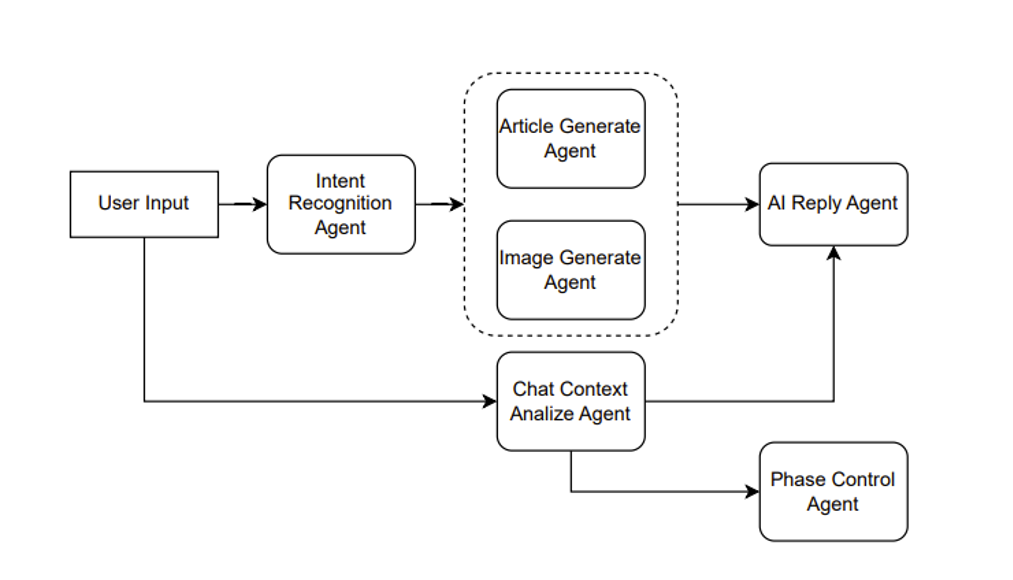 Figure 10. Agent combination for assisting in creation
Figure 10. Agent combination for assisting in creation
假设用户输入一个请求,说“帮我写一篇伦敦游记”, 那么 Intent Recognition Agent 首先做一个意图识别,意图识别也就是利用 ChatGPT 做一次分类任务。假设识别出用户的意图是文章生成,则接着调用 Article Generate Agent。
另一方面,用户当前的输入与历史的输入可以组成一个上下文,输入给 Chat Context Analyze Agent。当前例子中,这个 agent 分析出的结果传入后面的 AI Reply Agent 和 Phase Control Agent的。
AI Reply Agent 就是用来生成 AI 回复用户的语句,假设我们的产品前端并不只有一个文章,另一个敌方还有一个框用来显示 AI 引导用户创作文章的语句,则这个 AI Reply Agent 就是用来干这个事情。将上下文的分析与文章一同提交给 ChatGPT,让其根据分析结果结合文章生成一个合适的回复。例如通过分析发现用户只是在通过聊天调整文章内容,而不知道 AI 还能控制文章的艺术意境,则可以回复用户你可以尝试着对我说“调整文章的艺术意境为非现实主义风格”。
Phase Control Agent 则是用来管理用户的阶段,对于 ChatGPT 而言也可以是一个分类任务,例如阶段分为[文章主旨,文章风格,文章模板,文章意境]等等。例如 AI 判断可以进行文章模板的制作了,前端可以产生几个模板选择的按钮。
使用不同的 Agent 来处理用户输入的不同任务,包括意图识别、Chat Context 分析、AI 回复生成和阶段控制,从而协同工作,为用户生成一篇伦敦游记的文章,提供不同方面的帮助和引导,例如调整文章的艺术意境、选择文章模板等。这样可以通过多个 Agent 的协作,使用户获得更加个性化和满意的文章生成体验。
Prompt 微调
LLM 虽然很厉害,但离统治人类的 AI 还相差甚远。眼下有个最直观的痛点就是 LLM 的模型参数太多,基于 LLM 的模型微调变得成本巨大。例如 GPT-3 模型的参数量级达到了 175 Billion ,只有行业大头才有这种财力可以微调 LLM 模型,对于小而精的公司而言该怎么办呢。无需担心,算法科学家们为我们创新了一个叫做 prompt tuning 的概念。
Prompt tuning 简单理解就是针对prompt进行微调操作,区别于传统的 fine-tuning,优势在于更快捷, prompt tuning 仅需微调 prompt 相关的参数从而去逼近 fine-tuning 的效果。
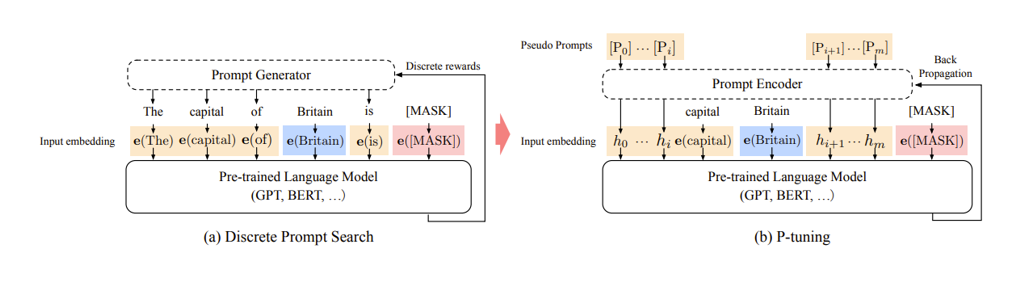 Figure 11. Prompt learning
Figure 11. Prompt learning
什么是 prompt 相关的参数,如图所示,prompt tuning 是将 prompt 从一些的自然语言文本设定成了由数字组成的序列向量。本身 AI 也会将文本从预训练模型中提取向量从而进行后续的计算,只是在模型迭代过程中,这些向量并不会跟着迭代,因为这些向量于文本绑定住了。但是后来发现这些向量即便跟着迭代也无妨,虽然对于人类而言这些向量迭代更新后在物理世界已经找不到对应的自然语言文本可以表述出意思。但对于 AI 来讲,文本反而无意义,prompt 向量随着训练会将 prompt 变得越来越符合业务场景。
假设一句 prompt 由 20 个单词组成,按照 GPT3 的设定每个单词映射的向量维度是12288,20个单词便是245760,理论上需要训练的参数只有245760个,相比175 billion 的量级,245760这个数字可以忽略不计,当然也会增加一些额外的辅助参数,但同样其数量也可忽略不计。
问题来了,这么少的参数真的能逼近fine tuning 的效果吗,当然还是有一定的局限性。如下图所示,蓝色部分代表初版的 prompt tuning, 可以发现 prompt tuning 仅有在模型参数量级达到一定程度是才有效果。虽然这可以解决大多数的场景,但在某些具体垂直领域的应用场景下则未必有用。因为垂直领域的微调往往不需要综合的 LLM 预训练模型,仅需垂直领域的 LLM 模型即可,但是相对的,模型参数不会那么大。所以随着发展,改版后的 prompt tuning 效果可以完全取代 fine-tuning。下图中的黄色部分展示的就是 prompt tuning v2 也就是第二版本的 prompt tuning 的效果。
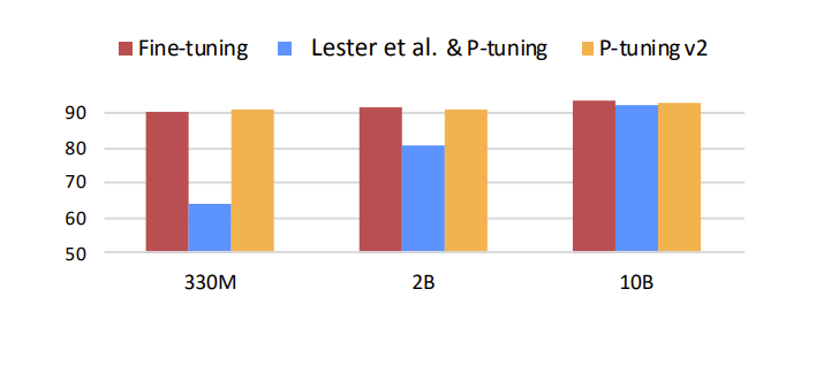 Figure 12. Prompt learning parameters
Figure 12. Prompt learning parameters
V2 的改进是将原本仅在最初层输入的连续 prompt 向量,改为在模型传递时每一个神经网络层前均输入连续 prompt 向量,如下图所示。
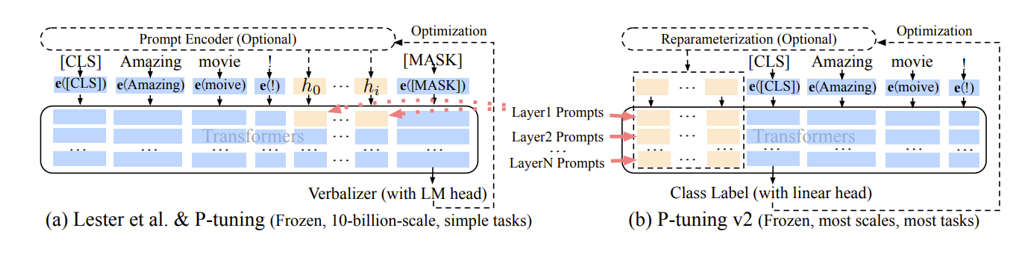 Figure 13. Prompt learning v2
Figure 13. Prompt learning v2
还是以 GPT3 模型为例,GPT3 总从有96层网络,假设 prompt 由20个单词组成,每个单词映射的向量维度是12288,则所需要训练的参数量 = 96 * 20 * 12288 =23592960。是175 billion 的万分之1.35。这个数字虽不足以忽略不计,但相对而言也非常小。
未来可能会有 prompt tuning v3, v4 等问世,甚至我们可以自己加一些创新改进 prompt tuning,例如加入长短期记忆网络的设定。(因为原版的 prompt tuning v2 就像是一个大型的 RNN, 我们可以像改进RNN 一般去改进prompt tuning v2)。总之就目前而言,prompt tuning 使得微调 LLM 变得可行,未来一定会有很多垂直领域的优秀模型诞生。
总结
Large Language Models (LLMs) 和 Web3 技术的整合为去中心化金融(DeFi)领域带来了巨大的创新和发展机遇。通过利用 LLMs 的能力,应用程序可以对大量不同数据源进行全面分析,生成实时的投资机会警报,并根据用户输入和先前的交互提供定制建议。LLMs 与区块链技术的结合还使得智能合约的创建成为可能,这些合约可以自主地执行交易并理解自然语言输入,从而促进无缝和高效的用户体验。
这种先进技术的融合有能力彻底改变 DeFi 领域,并开辟出一条为投资者、交易者和参与去中心化生态系统的个体提供新型解决方案的道路。随着 Web3 技术的日益普及,LLMs 创造复杂且可靠解决方案的潜力也在扩大,这些解决方案提高了去中心化应用程序的功能和可用性。总之,LLMs 与 Web3 技术的整合为 DeFi 领域提供了强大的工具集,提供了有深度的分析、个性化的建议和自动化的交易执行,为该领域的创新和改革提供了广泛的可能性。
1.资讯内容不构成投资建议,投资者应独立决策并自行承担风险
2.本文版权归属原作所有,仅代表作者本人观点,不代表本站的观点或立场
您可能感兴趣
-
 解读CKB版 “闪电网络” Fiber Network:比特币可编程性扩展的另一种思路
解读CKB版 “闪电网络” Fiber Network:比特币可编程性扩展的另一种思路作者:NingNing行业周期与宏观金融周期共振,加密行业正处在与 2019 年相似的整体性迷茫之中,现阶段不仅流动性枯竭,叙事貌似也在枯竭。市场不但对 VC 叙事兴趣阙如,对反 VC 的 Meme 叙事也已经疲倦。就像每次哲学危机,人们都会回归柏拉图寻找出路,当加密行业危机时,我们也需要回归比特币、回归中本聪。正如 CKB 生态 RGB++ 协议创始人 Cipher 在最新 Blog 里所阐述的,加密行业需要对以太坊 “链上计算” 的路径依赖进行反思,回归P2P经济学,让计算归于链下,让验证归于链上。因
-
 面对NFL球员工会起诉,“退圈”的DraftKings竟主动承认NFT是证券?
面对NFL球员工会起诉,“退圈”的DraftKings竟主动承认NFT是证券?作者:Zen,PANews近日,美国国家橄榄球联盟球员协会 (NFLPA) 指控数字体育娱乐和游戏公司DraftKings 逃避了其 NFT 球员许可协议的付款义务。在放弃NFT业务后,涉嫌出售未注册证券而遭到集体诉讼的DraftKings又背上了一起官司。而有趣的是,在与NFLPA的纠纷中,DraftKings的立场似乎已从反驳转变为积极承认“NFT就是证券”。放弃NFT业务:驳回集体诉讼的动议遭到否决今年7月底,Draftkings在给用户的电子邮件中表示:“经过慎重考虑,DraftKings 决定终
-
 简析两种最新比特币智能合约实现方案:OP_NET与Arch有何区别?
简析两种最新比特币智能合约实现方案:OP_NET与Arch有何区别?作者:Cookie过去半个月,OP_NET 与 Arch 这两个比特币主网上的智能合约实现方案引发了较多的讨论。有意思的事情是,OP_NET 这个名字与大家熟悉的 OP_CAT 很像,都以「OP_」开头,具有很强的、让大家认为这哥俩差不多的迷惑性。所以,在开篇要和大家先提一嘴 OP_CAT。首先,OP_CAT 是比特币操作码,从去年开始有以「量子猫」Quantum Cats,也就是「大巫师」Taproot Wizards 的创始人 Udi Wertheimer 为首的社区力量一直在呼喊要「复活」OP_CA
-
 争议不断,以太坊正在失去“万链之王”的权威
争议不断,以太坊正在失去“万链之王”的权威作者:Climber,金色财经近期围绕以太坊的话题和争议越来越多,不仅 Vitalik 本人需要下场解释观点,就连以太坊基金会也要发布公告来平息社区的质疑声。在本轮牛市周期中,以太坊的表现可谓平平。而美国以太坊现货 ETF 的通过也并未让 ETH 走势如投资者期待般爆发,相反却在币价方面越走越低。这就不免让有着「万链之王」美誉的以太坊逐渐失去投资者和社区的尊重,进而质疑起有关以太坊的方方面面。争议不断,以太坊亟需重塑权威最近一段时间以来社区成员对 Vitalik 言论观点、以太坊基金会乃至以太坊生态系统的
-
 从《黑神话:悟空》谈起,GameFi何时能取得真经?
从《黑神话:悟空》谈起,GameFi何时能取得真经?作者:YBB Capital Researcher Zeke前言本文是市场垃圾时间中的一些闲聊,需要对传统游戏市场有一定程度了解。大家可以把这篇文章当作日记或者随想观看,这些只是我在游玩《黑神话:悟空》之后对GameFi的一些粗浅思考,以及对这个赛道未来的看法。一、游戏科学的九九八十一难三天全网销量破千万、Steam玩家同时在线峰值破235万、多家品牌联名周边销售爆火、国家级媒体多次采访、多个游戏取景地可凭游戏通关记录终身免费进入、86版《西游记》YouTube观看量超400万。以上,是《黑神话:悟空》上
-
 Gavin Wood:如何防止女巫攻击进行有效空投?
Gavin Wood:如何防止女巫攻击进行有效空投?演讲:Gavin WoodGavin 近期一直在关注的女巫攻击(civil resistance)的问题,PolkaWorld 回顾了 Gavin Wood 博士在 Polkadot Decoded 2024 上的主题演讲,想要探究 Gavin 在如何防止女巫攻击上的一些见解。什么是女巫攻击?你们可能知道,我一直在研究一些项目,我在编写灰皮书,专注于 JAM 项目,也在这个方向上做了一些代码的工作。实际上,在过去的两年时间里,我一直在思考一个非常关键的问题,这个问题在这个领域中非常重要,那就是如何防止女巫
-
 市场热议,链抽象将成加密新叙事?
市场热议,链抽象将成加密新叙事?2024年,加密货币领域的技术创新持续加速,链抽象(Chain Abstraction)逐渐成为行业内的焦点。链抽象技术的核心在于通过隐藏底层技术的复杂性,让用户能够更加便捷地在多个区块链之间进行操作。传统的区块链技术通常要求用户掌握不同链的操作流程,并需要应对跨链操作中的技术难题,这极大地吸引了新用户的进入。而链抽象的出现,则为这些问题提供了有效的解决方案,成为Web3建设不可忽视的重要一环。01、什么是链抽象及其作用链抽象能够将不同的区块链之间的差异整合在一个统一的操作界面中,使得用户只需一个账户即可
-
今日日报|马斯克和特斯拉赢得“被指控操纵狗狗币”的诉讼;稳定币支付平台Bridge完成5800万美元融资
今日要闻提示:马斯克和特斯拉赢得驳回指控他们操纵狗狗币的诉讼OpenAI和Anthropic已同意将其主要新AI模型在发布前共享给美国政府OKX将上线Hamster Kombat(HMSTR)现货交易X平台纽约总部将于9月13日关闭,预计将迁往得州萨尔瓦多总统布克尔成为《时代》杂志最新一期封面人物稳定币支付公司Bridge完成5800万美元融资数据:MATIC、SHIB、UNI代币头部地址持仓均超50%网龙今年上半年通过出售2.9亿元的加密货币,获利5100万元人民币监管消息美国众议院计划在9月举行多场加
- 成交量排行
- 币种热搜榜
 泰达币
泰达币 比特币
比特币 以太坊
以太坊 First Digital USD
First Digital USD USD Coin
USD Coin Solana
Solana 瑞波币
瑞波币 狗狗币
狗狗币 Wormhole
Wormhole Pepedogwifhat
Pepedogwifhat 币安币
币安币 Sui
Sui Maker
Maker Fetch.AI
Fetch.AI SHIB
SHIB FIL
FIL EOS
EOS HT
HT CFX
CFX DYDX
DYDX FTT
FTT UNI
UNI CELO
CELO CAKE
CAKE GALA
GALA LPT
LPT