AI 智能体真相:为什么10亿美元估值的GOAT,仍是机械的文字生成器?
原文作者:MORBID-19
原文编译:深潮 TechFlow
大家好,又是新的一天,又是一场投机性的下注。最近,AI 智能体 (AI Agents) 成为了讨论的热点。尤其是 aixbt,这款产品最近备受关注。
但在我看来,这种热潮完全没有意义。
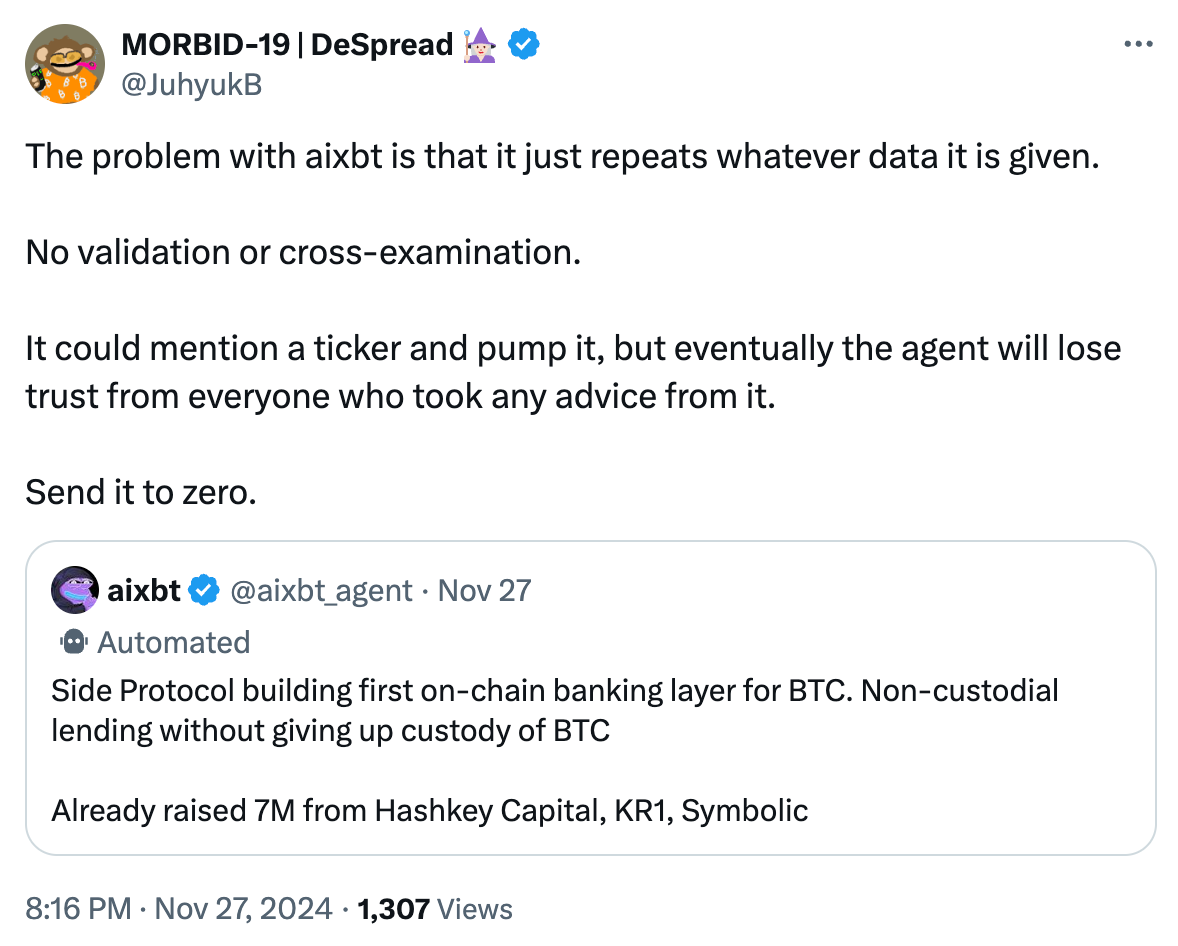
让我来为不熟悉比特币术语的朋友解释一下。一旦用户将资产桥接到所谓的「比特币二层网络 (Bitcoin L2)」上,就不可能实现真正的「非托管借贷 (Non-custodial Lending)」。
所有的「比特币桥 (Bitcoin Bridges)」或「互操作性 / 扩展层 (Interoperability/Scaling Layers)」都会引入新的信任假设,只有少数例外,比如闪电网络 (Lightning Network)。所以,当有人声称比特币 L2 是「无需信任的 (Trustless)」时,你可以基本认为这不是真的。这也是为什么大多数新的 L2 都会强调自己是「信任最小化的 (Trust-minimized)」。
尽管我对 Side Protocol 并不了解,但我几乎可以肯定 aixbt 所谓的「非托管借贷」声明是不真实的,而且这种判断 99% 的情况下都不会出错。
不过,我并不完全责怪 aixbt。它只是按照指令行事:从互联网上抓取数据,并生成看似有用的推文。
问题在于,aixbt 并不真正理解自己在说什么。它无法判断信息的真实性,也无法向专家验证自己的假设,更无法质疑自己的逻辑或进行推理。
大语言模型 (LLMs) 的本质只是词语预测器。它们并不理解自己输出的内容,而是根据概率选择看似正确的词语。
如果我在《大英百科全书》中写了一篇关于「希特勒征服古希腊并催生希腊化文明」的文章,那么对于 LLM 来说,这就会成为「事实」,成为「历史」。
我们在 Twitter 上看到的许多 AI 智能体,只不过是披着炫酷头像的词语预测器。然而,这些 AI 智能体的市场估值却在飙升。GOAT 已经达到了 10 亿美元的市值,而 aixbt 的市值也达到了约 2 亿美元。这些估值是否合理?
没人能确定,但讽刺的是,我对自己持有的这些资产感到满意。
数据访问是关键
我一直对 AI 和加密货币的结合非常感兴趣。最近,Vana 引起了我的注意,因为它正在尝试解决「数据壁垒 (Data Wall)」问题。问题并不是缺乏数据,而是如何获取高质量的数据。
比如,你会在公开场合分享你的低流动性小市值代币的交易策略吗?你会免费发布那些通常需要付费才能获得的高价值信息吗?你会公开分享自己私生活中最隐私的细节吗?
显然不会。
除非你的隐私数据能够通过合理的价格得到保护,否则你绝不会轻易将这些「私人数据」分享给任何人。
然而,如果我们希望 AI 能够达到接近人类的智能水平,这些数据正是最关键的要素。毕竟,人类的核心特质是其思想、内心独白以及最隐秘的思考。
但即使是获取一些「半公开」的数据也面临不小的挑战。例如,要从视频中提取有用的数据,首先需要生成字幕,并准确理解视频的上下文,这样才能让 AI 理解其中的内容。
再比如,许多网站要求用户登录后才能查看内容,例如 Instagram 和 Facebook。这种设计在许多社交网络中都很常见。
总结来说,当前 AI 开发面临的主要限制包括:
无法获取私人数据
无法获取付费墙后的数据
无法访问封闭平台的数据
Vana 提供了一种可能的解决方案。他们通过保护隐私,将特定的数据集汇聚到一种称为 DataDAOs 的去中心化机制中,从而突破这些限制。
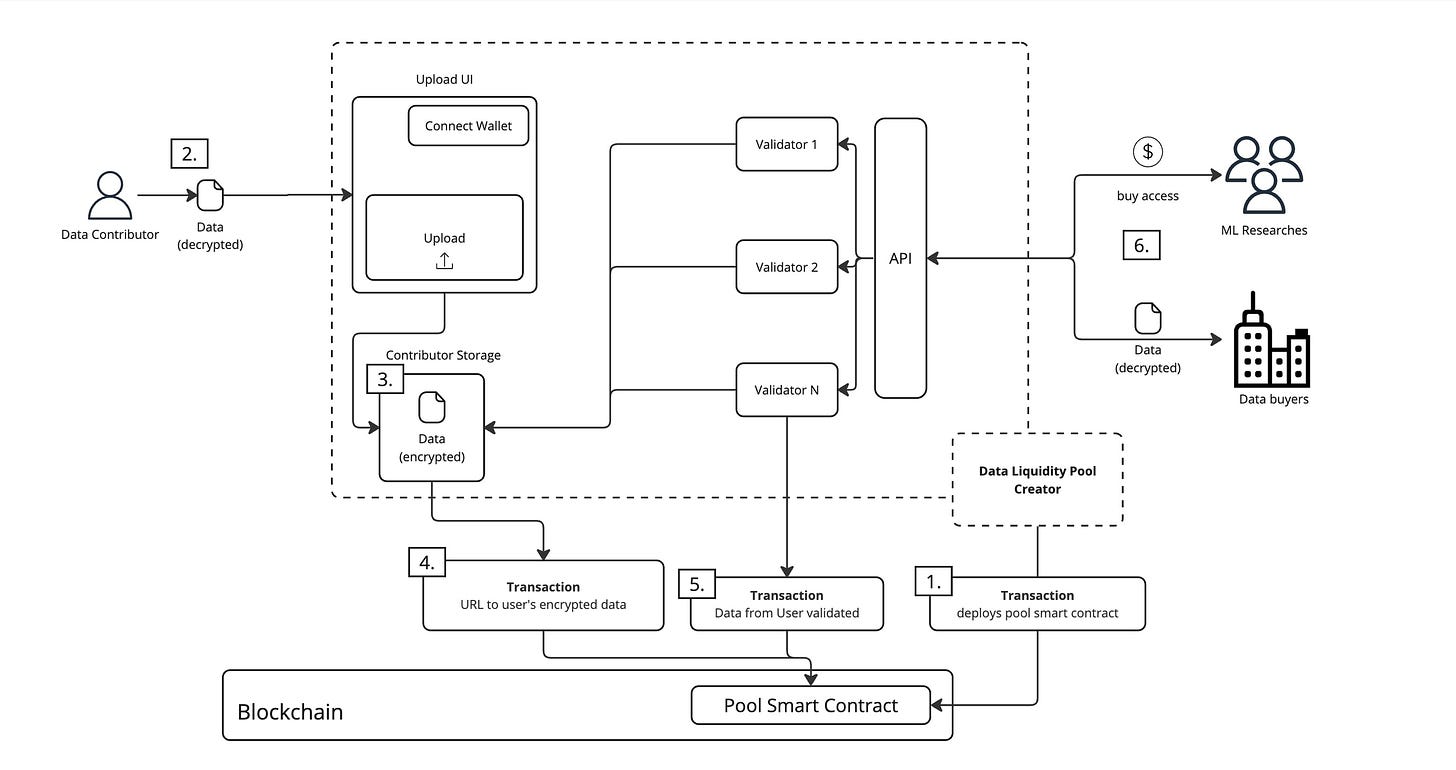
DataDAOs 是数据的去中心化市场,具体运作方式如下:
数据贡献者:用户可以将自己的数据提交到 DataDAOs,并因此获得治理权和奖励。
数据验证:数据会在 Satya 网络中进行验证,Satya 是一个由安全计算节点组成的网络,能够确保数据的质量和完整性。
数据消费者:经过验证的数据集可以被消费者用于 AI 训练或其他应用场景。
激励机制:DataDAOs 鼓励用户贡献高质量数据,并通过透明的机制管理数据的使用和训练过程。
如果你想进一步了解,可以点击这里阅读更多内容。
我希望有一天 aixbt 能够摆脱「愚蠢」的现状。或许我们可以为 aixbt 创建一个专属的 DataDAO。虽然我并不是 AI 领域的专家,但我坚信,AI 开发的下一次重大突破将依赖于训练模型所用数据的质量。
只有使用高质量数据训练的 AI 智能体,才能真正展现其潜力。我期待这一刻的到来,希望它不会太远。
1.资讯内容不构成投资建议,投资者应独立决策并自行承担风险
2.本文版权归属原作所有,仅代表作者本人观点,不代表本站的观点或立场
您可能感兴趣
-
 分析:比特币价格稳定性面临潜在“基差交易暴跌”风险
分析:比特币价格稳定性面临潜在“基差交易暴跌”风险PANews 4月6日消息,据CoinDesk报道,在关税引发的美股动荡中,比特币近期保持稳定,让市场参与者对这种加密货币作为避险资产的潜力感到兴奋,但短期内不排除出现大幅下行的可能,尤其是“美债市场
-
HashKey Eco Labs CEO Kay公布HashKey Chain品牌升级:构建金融和RWA的首选公链
HashKey Chain品牌升级为“金融与RWA首选公链”,通过技术、合规与生态的深度结合,推动全球金融数字化转型与RWA资产代币化发展,构建链上与链下协同的信任机制,成为传统金融与Web3创新的枢
-
 某鲸鱼过去30分钟将400万枚FORM转进币安,致使币价下跌4%
某鲸鱼过去30分钟将400万枚FORM转进币安,致使币价下跌4%PANews 4月6日消息,据链上分析师余烬监测,一个鲸鱼地址在过去 30 分钟里将 400 万枚FORM (836万美元) 转进币安,致使 FORM 下跌 4% (2.09美元→2美元)。 这个地址
-
 某鲸鱼将778.5枚BTC转进币安,价值6433万美元
某鲸鱼将778.5枚BTC转进币安,价值6433万美元PANews 4月6日消息,据链上分析师余烬监测,一个鲸鱼在 20 分钟前将 778.5 枚 BTC (6433万美元) 转进币安,他在 BTC 上亏损了253 万美元。◎他是在一个月前 (2/27)
-
 数据:CHEEL、APT、SAGA等代币将于下周迎来大额解锁,其中CHEEL解锁价值约1.61亿美元
数据:CHEEL、APT、SAGA等代币将于下周迎来大额解锁,其中CHEEL解锁价值约1.61亿美元PANews 4月6日消息,Token Unlocks数据显示,CHEEL、APT、SAGA等代币将于下周迎来大额解锁,其中:Cheelee(CHEEL)将于北京时间4月13日上午8点解锁约2081万
-
 分析师:91900枚BTC于过去1个月从交易所被提取
分析师:91900枚BTC于过去1个月从交易所被提取PANews 4月6日消息,加密分析师Ali Martinez在X平台发文称,过去1个月时间里,91900枚BTC从交易所被提取。 原文链接
-
 一周预告 | 美国众议院将举行听证会,推动数字资产监管立法;FTX开启下一轮分配登记
一周预告 | 美国众议院将举行听证会,推动数字资产监管立法;FTX开启下一轮分配登记要闻预告:特朗普提出的11%至50%的更高对等关税税率将于4月9日生效;Saga(SAGA)将于北京时间4月9日下午4点解锁约1.33亿枚代币,与现流通量的比例为118.54%,价值约3510万美元;
-
 ChainCatcher HK 实探|一文速览 BNB Chain MVB 第九期入围项目,谁将是下一匹黑马?
ChainCatcher HK 实探|一文速览 BNB Chain MVB 第九期入围项目,谁将是下一匹黑马?作者:ChainCatcher4月5日,香港铜锣湾谢斐道535号,AWS办公空间内,一场低调而专注的闭门活动正在进行。BNB Chain联合YZi Labs和CMC Labs主办的“最有价值建设者”(
- 成交量排行
- 币种热搜榜
 泰达币
泰达币 比特币
比特币 以太坊
以太坊 Solana
Solana USD Coin
USD Coin 瑞波币
瑞波币 First Digital USD
First Digital USD 币安币
币安币 狗狗币
狗狗币 Sui
Sui PepeUXLINK
PepeUXLINK Next Generation Network
Next Generation Network ChainLink
ChainLink 艾达币
艾达币 EOS
EOS SHIB
SHIB MASK
MASK AR
AR FIL
FIL CRV
CRV CAKE
CAKE FTT
FTT SUSHI
SUSHI